
How Artificial Intelligence Works
“Artificial Intelligence, Deep Learning, Machine Learning. Whatever you’re doing, if you don’t understand it, learn it. Because otherwise you’re going to be a dinosaur within three years.”
Mark Cuban, billionaire investor
“A breakthrough in Machine Learning will be worth 10 Microsofts.”
Bill Gates
“We are now solving problems with machine learning and artificial intelligence that were in the realm of science fiction for the last several decades.”
Jeff Bezos, CEO and founder, Amazon
Artificial intelligence is described as technology with the ability to achieve complex goals. So the question becomes what is a goal? Is the goal of a self-driving car to travel down the street the same as the goal of a human male to start a family? Or can the goal of an email spam filter be compared with the goal of a human social worker to make a difference in the world? When we give a machine a goal to achieve a task, can we equate that to the goals of human beings? Nelson Mandela had a goal to free South Africa of apartheid. Charles Darwin had a goal to understand our provenance. Winston Churchill, to defeat Nazi Germany. Can we equate these lofty human goals with the functional goals of machines? The answer is that this may not be a fair comparison. The reason is that we have been comparing the goals of human beings with a very limited type of AI that’s called “narrow AI.”
TYPES OF AI
Artificial intelligence divides into two main types: General artificial intelligence and narrow AI, which breaks down into further subfields:
- Artificial general intelligence
- Narrow AI
- Robotics
- Expert systems
- Automated reasoning
- Swarm intelligence
- Speech recognition
- Natural language processing
- Machine learning
- Supervised
- Unsupervised
- Reinforcement learning
- Deep learning
- Machine vision
- Deep reinforcement learning
- Deep learning
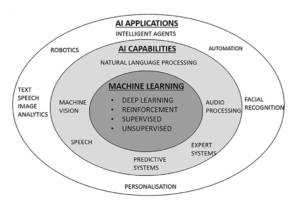
Figure 4: The constellation of AI technologies and business applications, based on an image from the book Human + Machine, 2018 Accenture Global Solutions21
ARTIFICIAL GENERAL INTELLIGENCE
Artificial general intelligence (AGI) is the transformative AI that could culminate in the singularity, a watershed moment when machine intelligence exceeds all human intelligence, giving birth to a superintelligence22 . AGI specifically refers to software that can solve a variety of complex problems in a variety of different domains and that controls itself autonomously.
This is the AI that could have important goals that would be just like human goals. It could even have grander goals than most of us, such as ending poverty, preventing malaria or curing cancer, traveling to other planets and more. Or in many doomsday scenarios, for example, in the movie The Terminator, AGI could have the goal of destroying all human life.
AGI was the original focus of the first AI researchers, such as Turing, Good, McCarthy, Minsky and others. However, due to the demonstrated difficulty of the problem, not many AI researchers are focused on AGI anymore. Hype surrounding the singularity has given AGI a bit of a bad reputation, as if creating artificial general intelligence was pure science fiction. Yet, while AGI is a recurrent theme for sci-fi movies, it is, by all known science, absolutely possible. Like nanotechnology, it is merely an engineering problem, though an extremely difficult one. Among the few companies explicitly focused on AGI are Google DeepMind, the London-based company led by Demis Hassabis; Elemental Cognition founded by David Ferrucci, who built IBM Watson and led its victory on Jeopardy!; and Open AI, a nonprofit AI research company backed by Elon Musk that is focused on building safe artificial general intelligence.
NARROW AI
Narrow AI is the only form of artificial intelligence that humanity has achieved so far. Narrow AI is good at performing a single task, such as playing chess, finding patterns in data, making recommendations, making predictions or planning routes. Speech and image recognition are narrow AI, even if they seem remark-ably human. Google’s translation engine is a form of narrow artificial intelligence. The technology behind self-driving cars is still considered a type of narrow AI, or more precisely, an ensemble of several narrow AIs.
Narrow AI is sometimes also referred to as “weak AI.” However, that doesn’t mean that narrow AI is not useful. It is excellent at fulfilling its narrow purpose, either physically or cognitively. It is narrow AI that’s threatening to displace millions of human jobs. And it’s narrow AI that finds patterns in data that humans may not be able to find. It is also narrow AI that has bested the best human minds in chess, Go and other challenging games. Narrow AI is also the AI that you could use to help your business.
MACHINE LEARNING
Machine learning is the most widely used and potent form of narrow AI. Machine learning is a specific subset of narrow AI that trains a machine how to learn. It is a method of data analysis that automates analytical model building. Machine learning models use algorithms to look for patterns in data and then try to draw conclusions.
The world is filled with data. Machine learning offers the potential of deriving meaning from all of that data. The sheer scale of the quintillions of data points produced every day surpasses humans’ ability to analyze. The only way to understand all this data is through automated systems such as machine learning. Data is not useful by itself, but enormous value can be derived from data through analyzing it, as British mathematician Clive Humby explains:
Data is the new oil. It’s valuable, but if unrefined, it cannot really be used. It has to be changed into gas, plastic, chemicals, etc. to create a valuable entity that drives profitable activity; so must data be broken down and analyzed for it to have value.
Machine learning is based on the idea that machines can analyze pat-terns in data through algorithms and that these patterns can be used to make predictions. The term “algorithm” comes from the Latinization of the name Al-Khwarizmi, the ninth-century Persian mathematician who pioneered algebra. An algorithm sounds wonderfully complex, but it is simply a set of instructions. It is a highly specific set of instructions that even something as literal as a machine can follow to complete a calculation or solve a problem. For example, a cooking recipe is not an algorithm because it is not precise enough about every action that needs to be taken. You don’t know how many seconds to pour the milk or to exactly what temperature to heat the cooktop.
Here is an example of an algorithm for finding the largest number on a list:
find_max(). Problem: Given a list of positive numbers, return the largest number on the list. Inputs: A list L of positive numbers. This list must contain at least one number. (Asking for the largest number in a list of no numbers is not a meaningful question.) Outputs: A number n, which will be the largest number on the list. Algorithm: Set max to 0. For each number x in the list L, compare it to max. If x is larger, set max to x. max is now set to the largest number on the list.
Once designed, the algorithm needs to be written in a language com-puters understand, at which point it becomes a program. This is our algorithm “find max” in Python programming language:
def find_max (L): max = 0 for x in L: if x > max: max = x return max
LEARNING ALGORITHMS
Normal algorithms like “find max” have an input and an output. Data goes in the computer, the algorithm works on it and out comes the result. The genius of machine learning is to reverse this process. The data and the result go in, and the underlying pattern that turned one into another is uncovered by a learning algorithm, or learner. We then have a trained learning algorithm we can apply to new data. Machine learning can find patterns in extremely complex datasets and, as a result, make highly accurate predictions.
USES OF MACHINE LEARNING
Machine learning is all around us in the products we use today. All of the following are powered by machine learning:
- Social media personalization, face recognition and ad targeting
- Recommending a video to watch, such as a movie on Netflix or Amazon Prime
- Google searches, from the actual query to understanding its mean-ing, then personalizing the results
- Customer service technology, such as chatbots that answer ques-tions through LiveChat
- Email spam filtering and malware alerts
- GPS systems that predict traffic
- Virtual personal assistants like Alexa and Siri that use speech
- Crime- and fraud-detection systems that identify abnormal behavior
- Financial traders that use automated systems to help them make trades
- Medical diagnosis systems that can assess your symptoms and send you to a doctor
- Business and customer analytics to identify valuable customers and predictive analytics to find selling opportunities
TYPES OF LEARNERS
US computer science professor Pedro Domingos, author of The Master Algorithm23, explains that just a few learners are responsible for the great majority of machine learning applications. For example, a learn-er algorithm called “naïve Bayes,” based on Bayes’ theorem, can be used to diagnose medical conditions or filter out spam email. “Decision tree” learners are used for credit card applications and DNA analysis. “Nearest neighbor” is used for tasks ranging from moving robot hands to recommending films playing in movie theaters.
Amazon recommendations use a learner called “affinity analysis.” It is a simple cross-selling and upselling strategy. The algorithm has learned that people who buy product Y often also buy product X, Z, T. So when you click on product Y, the affinity analysis algorithm kicks in and rec-ommends products X, Z and T. You may not buy any of these products but instead go for product R. The affinity analysis then learns from your behavior and this is fed into the model so that next time it may also offer R. It is, therefore, continually improving performance. These learners consist of just a few hundred lines of code, which makes them remark-ably simple compared to programs they replace, which can house mil-lions of lines of code. AI systems are, at their core, just chains of these algorithms tied together. Nick Polson and James Scott explain in their book, AIQ: How Artificial Intelligence Works and How We can Harness Its Power for a Better World:
On its own, an algorithm is not smarter than a power drill; it just does one thing very well, like sorting a list of numbers or searching the web for pictures of cute animals. But if you chain lots of algorithms together in a clever way, you can produce AI: a domain-specific illu-sion of intelligent behaviour. For example, take a digital assistant like Google Home, to which you might pose a question like “Where can I find the best breakfast tacos in Austin?” This query sets off a chain reaction of algorithms. And that’s AI. Pretty much every AI system . . . follows the same pipeline of algorithm system.24
THE SIMPLICITY OF COMPUTING
If algorithms now seem very simple, computers are even simpler. At the core of every computer are transistors that switch on and off. The late MIT professor Claude Shannon, realized as an MIT master’s student that, when these transistors switch on and off, it is a form of logical reasoning. The master’s thesis written by Shannon, an American contemporary and friend of Alan Turing, became the most famous and possibly the most important master’s thesis of the twentieth century.25 Domingos explains Shannon’s finding:
If transistor A turns on only when B and C are both on, it’s doing a tiny piece of logical reasoning. If A turns on when either B or C is on, that’s another tiny logical operation. And if A turns on whenever B is off, and vice versa, that’s a third operation. Believe it or not, every algorithm, no matter how complex, can be reduced to just these three operations: AND, OR and NOT operations.26
The transistors in a computer turn on and off in different orders billions of times per second to run the technology that shapes our lives, from mobile phones to credit cards, GPS systems, online shopping and much more. The challenge is how to develop algorithms sophisticated enough for all these operations. Facebook, for example, would have to write a program to show relevant updates to each of its 2.27 billion users. Amazon would have to individually code its product recommen-dations to all of its 310 million users. Netflix would need to write a program to offer different and relevant films to cater to the specific tastes of its 158 million subscribers. There aren’t enough programmers and developers in the world to write all these codes, and even if they tried, they could not layer in the complexity required by so many differ-ent users. But learning algorithms can learn about every single user and personalize the experience for each one, and that is why we need them.
THE DEMOCRATIZING EFFECT OF OPEN-SOURCE CODE
One myth that I would like to shatter in this book is that AI re-quires millions of dollars in investment, or that AI is just an arms race controlled only by tech giants like Google, Facebook, Amazon and others. Yes, such companies are investing a fortune in AI. For exam-ple, Intel, Microsoft, Amazon and Google alone invested $42 billion in research and development in 2018. They also have access to vast data, and, as we explained earlier, this gives them a major advantage in their fields.
But data is also verticalized in industries where certain businesses dominate. Google may have the best search query data, but it does not have all the data in industries such as health care, financial services or automotive engineering. Tesla has managed to accumulate more real -world data on self-driving cars than Google, even though Google has a five- year head start on research in the field. Tesla turned all its customers into data gatherers by installing relatively cheap equipment in all its commercial vehicles, letting its drivers collect data when they use self-driving features such as self -parking or autosteer (autopilot) for crash avoidance. Google collects data for its self-driving car tech-nology on a much smaller scale, gathering data with high-end sens-ing equipment only on its own fleet of cars. As a result, after six years, Google had 15 million miles of self -driving data, while Tesla had more than three times this much, with 47 million miles of data, after just six months. The lesson is that data is not just the preserve of Google, and you can deploy creative strategies to gather data.
AI is also in the hands of thousands of people through open source libraries, which are repositories of software that is freely available to anyone. To build the very best, most robust software, there are ad-vantages in making it open source. This means that millions of de-velopers can work on it and improve it. Open source both improves the software and democratizes it by allowing free access to everyone. Since 2015, Google has made its deep- learning engine, TensorFlow, open source. In 2015, Facebook made the server that runs its Big Sur AI algorithms open source. And Google has open -sourced Parsey McParseFace, an AI language-parsing tool. These AI libraries are ac-cessible to thousands of PhDs, developers and even hobbyists.
TRAINING AND PREDICTION
The first stage of machine learning is training, which involves feeding data into the machine. It is important to feed exactly the right data for the specific question you want to answer. The machine learns through the discovery of patterns. As Andrew Ng of Stanford and Coursera, the open online learning platform he cofounded puts it: “You throw a ton of data at the algorithm and let the data speak and have the software auto-matically learn from the data.”
The machine uses learning algorithms to simplify the reality and trans-form this discovery into a model. Therefore, the learning stage is used to describe the data and to summarize it as a model. Creating models is something machines can do far more quickly and more effectively than humans, according to author and Babson College distinguished professor Thomas Davenport:
“Humans can typically create one or two good models a week; machine learning can create thousands of models a week.”27
MACHINE LEARNING LIFE CYCLE
- Define the question / problem.
- Gather data.
- Train algorithm.
- Test the algorithm.
- Collect feedback.
- Refine the algorithm.
- Loop 3–6 until the results are satisfying.
- Use the model to make a prediction.
Once the algorithm gets really good at drawing the right conclusions, it applies that knowledge to new sets of data.
When the machine learning model is built, it is possible to apply it to never before seen data to make predictions. The new data goes through the model and a prediction is made. This is an important capability of machine learning. There is no need to update the rules or retrain the model. You can even use the model previously trained to make inferences about new data.
Prediction is not just about the future but also the present. When banks decide that a transaction is fraudulent, they use prediction. Some 80 percent of credit card fraud was detected in the 1990s, and today it is 99.9 percent, thanks to prediction. When the computer I am writing this book on corrects my text in real time, it uses prediction. Prediction, then, is fundamentally about providing missing information:
[Making] predictions is the process of filling in missing informa-tion. Prediction takes all the information you have, often called “data”? And it uses it to generate information you don’t have.28
PREDICTION AND INTELLIGENCE
The core function of machine learning is making predictions. So, you may ask, why do we call it artificial intelligence if it is just about making predictions? The reason is prediction is a key component in human intelligence and how the brain works. Our very perception is based on prediction, as Jeff Hawkins explains.29 Imagine you are in a room looking at all the objects around you. Without performing any action, somehow you “understand” the room. Now, imagine that a new object appears in the room, such as a blue coffee cup. You know immediately the cup is new; it jumps out at you as not belonging. To notice this, neurons in your brain that were not active must have become active. How did these neurons notice that something is different? Because they are continuously making predictions.
The brain uses stored memories to constantly predict everything we see, feel and hear. It is as if your brain is saying, “Are the cur-tains on the wall? Yes. Are they grey? Yes. Is there a shadow on the wall from the sunlight? Yes. And so on. When you look around the room, your brain is using memories to make predictions about what it expects you to experience before you do. Jeff Hawkins comments in On Intelligence:
Prediction is so pervasive that what we “perceive”—that is, how the world appears to us—does not come solely from our senses. What we perceive is a combination of what we sense and of the brain’s memory-derived predictions. Prediction is not just one of the things your brain does. It is the primary function of the neocortex, and the foundation of intelligence.30
To illustrate just how fundamental prediction is to our intelligence, Hawkins gives a number of everyday examples: You step forward but miss the stairs and your brain instantly recognizes something is amiss and you readjust to maintain your balance; you listen to a melody and hear the next note in your mind before it is played; as someone talks, you just know what words they are going to say next; if I write “how now brown,” you have already thought “cow.” Hawkins points out that intelligence tests throughout school are really tests of predictive ability. For instance, given a sequence of numbers, what should the next one be? Science itself is an exercise in prediction, hypothesis and testing. Intelligence relies on making predictions about patterns in language, math and social situa-tions. Jeff Hawkins comments:31
These predictions are the essence of understanding. To know something means that you can make predictions about it. . . . We can now see where Alan Turing went wrong. Prediction, not be-havior, is the proof of intelligence.
PREDICTION AND ECONOMIC IMPACTS
Prediction then is the very foundation of intelligence, and machine learning’s use of prediction will have a fundamental economic impact. In Prediction Machines32, Ajay Agrawal, Joshua Gans and Avi Goldfarb — professors of economics at the Rotman School of Management in Toronto — examine the impact of machine learning from an economics perspective. They argue cheaper prediction will have a crucial economic impact affecting supply and demand, production and consumption, and prices and costs. When the price of something falls, we use more of it. When the price of something fundamental drops drastically, the world can change. For example, light became 400 times cheaper between the 1800s and now, leading to the world lighting up. When computers made arithmetic calculations cheap, this had a massive economic impact since more people had access to math and it was extended into more and more areas.
Cheaper prediction will be useful in traditional prediction tasks like forecasting but also in endless new domains. Cheaper prediction through machines will cause an economic impact on a par with per-sonal computers. Prediction machines may become so reliable and ef-fective that they change how organizations operate. Machine learning will not just be used to execute a strategy, it will change the strategy itself. Prediction through machine learning is an immensely powerful new technology.
HUMAN PREDICTION VS. MACHINE PREDICTION
Do we actually need machines to make predictions? Aren’t human be-ings good enough? Well, as US baseball legend Yogi Berra once observed, “It is tough to make predictions, especially about the future.”
Human beings are good at making predictions when there is little data, for example, seeing someone’s face once and then remembering it. However, humans normally make predictions on the basis of strong features, based on a small number of data points correlated to a specific outcome, normally with a cause and effect relationship; for example, in predicting whether someone will have a heart attack, strong predictive factors include a person’s weight and smoking.
Machine learning factors in strong features but it also takes into ac-count thousands of weak features, data points that may not be obvious but have predictive power when combined across millions of cases. This enables subtle correlations that are impossible for humans, but learning algorithms using complex mathematical relationships, such as nonlinearity, exceed even the best human minds in making predictions.
In Thinking, Fast and Slow, Daniel Kahneman demonstrates that algorithmic decisions are more accurate than human predictions. Even trained counsellors making predictions about the outcomes of their own students are less accurate than machines.33 More than fifty years of data from topics such as longevity of cancer patients, career satisfaction, the likelihood of violent crimes, the prices of goods and the successes of new businesses show that machines have done better than people. 34
That said, human and machine predictions are not mutually exclusive; we can make predictions together. For example, in 2016, a Harvard– MIT team of AI researchers won the Camelyon17 grand challenge, which focused on detecting breast cancer. The team’s deep learning algorithm made correct predictions with 92.5 percent accuracy, while a human pathologist’s predictions were 96.6 percent accurate. When AI researchers combined the predictions of their algorithm with those of a pathologist, the result was 99.5 percent accuracy. Partnering human and machine predictions created almost perfect predictions in this case. This speaks to the key role AI has in augmenting, rather than replacing, human beings.
DEEP LEARNING AND NEURAL NETWORKS
The state of the art type of machine learning that makes the most powerfully accurate predictions is called deep learning. In business, deep learning has been responsible for the most useful applications and, in fact, has led to renewed excitement in AI since 2013. Roboticist Daniela Rus, director of MIT’s Computer Science and Artificial Intel-ligence Laboratory (CSAIL), explains: “I think that today most peo-ple who say “AI” actually mean machine learning, and more than that, they mean deep learning within machine learning.” Most deep learning methods use neural network architectures, which is why deep learning models are often referred to as deep neural networks. The term “deep” usually refers to the number of hidden layers in the neural network. Traditional neural networks only contain two to three hidden layers, while deep networks can have as many as 150.
Deep learning differs from machine learning in the way it learns the structure of the data. Deep learning algorithms are constructed with connected layers. Each layer is composed of neurons, so named because they work in parallel, like the neurons in the human brain. As you read this sentence, neurons in your brain are active on differ-ent levels at the same time. Some neurons recognize shapes like the lines and dots in the letters. Other neurons combine these shapes to form ideas about what letter is being represented. These neurons send this information up to the syntactic level and onto the seman-tic level, recognizing whole words; neurons also send information to other neurons to derive the meaning of the words in the context of the sentence. These neurons share all this information in parallel, back and forth, up and down, side to side. This parallel characteristic is what inspired the parallelism in neural networks, as shown in the following diagram:
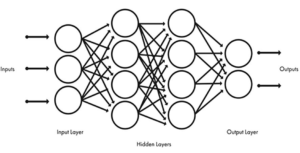
Figure 5: visual illustration of deep learning
HOW DEEP LEARNING WORKS
To understand deep learning and what makes it so effective, you have to understand parameters. A parameter is a number in your prediction equation that you choose to yield the best results. In AIQ35, authors Nick Polson and James Scott lay out their case that we used to use small models with small parameters to make predictions. Small models have a few parameters, while massive models have lots of parameters. For ex-ample, you could predict the maximum heart rate of someone for their age with this model: Max heart rate = 220 – age. This is a small model with just one parameter; the baseline of 220, from which you subtract your age. The problem is that such a simplistic model won’t be as accu-rate as a model with more parameters.
Using machine learning, we can fit models with hundreds of parameters. With deep learning, we can fit hundreds of thousands of parameters. For example, Google published information about a deep learning neural network model named Inception that could automatically label and recognize an image. The model involved 388,736 parameters, and its prediction was based on 1.5 billion arithmetic operations. In a world of big data, such massive models can make highly accurate and useful predictions in endless domains.
Deep learning has made AI much more powerful in recent years. For example, in November 2016, Google Translate was used to translate some Japanese text into English and this was the result:
Kilimanjaro is a 19,710 feet of the mountain covered with snow, and it said that the highest mountain in Africa.
The next day the Google translation had improved markedly:
Kilimanjaro is a mountain of 19,710 feet covered with snow and is said to be the highest mountain in Africa.36
The translation improved because Google had improved its machine learning engine for Google Translate by implementing deep learning.37 This enables many more parameters and arithmetic operations on masses of data such that predictions become incredibly accurate. As a Google engineer said: “When you go from 10,000 training examples to 10 billion training examples, it all starts to work. Data trumps everything.” 38
This highlights an important characteristic about machine learning and deep learning. Adding much more data can make models that are not working, suddenly work. This finding was highlighted in 2009 when three computer scientists from Google wrote a paper entitled The Unreasonable Effectiveness of Data. There is an unexpected phenomenon in machine learning that goes like this: Even a messy dataset with a billion items can be highly effective in tasks such as machine translation, for which machine learning using a clean dataset with a mere million items is unworkable. This is unexpected because a million is a big numer. So when we learn the algorithm doesn’t work, our intuition may tell us it won’t ever work. But what may, in fact, be needed is an even larger training set. As the controversial founder of Cambridge Analytica once said, “There is no data like more data.”
TYPES OF TRAINING
So what happens when you don’t have enough data? To make predictions without enough training data, we can use a specific type of machine learning called reinforcement learning. This is what Alan Turing brilliantly foresaw when he described a child-machine. Rather than preprogamming knowledge into a machine, you can build a machine like a child that learns itself and builds knowledge. Reinforcement learning enables machines to learn by trial and error, generating their own data.
We can only apply reinforcement learning in a simulated environment, as with chess or Go, which is why DeepMind was able to employ this technology so effectively. We couldn’t use reinforcement learning to generate data about self-driving cars on the road because to learn we would have to drive off 1,000 cliffs. But there are solutions for creating simulated environments, such as video games and test environments that are being used specifically to develop reinforcement learning AI systems.
Reinforcement learning is one of three fields of machine learning that are classified according to the type of supervision they get during training:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
SUPERVISED LEARNING
Supervised Learning is by the far the most widely used type of ma-chine learning. In supervised learning, the machine uses data that is labelled. For example, when an unwanted email comes into your inbox, and you mark it as spam, you are actually training a machine with labels. It learns how to classify new emails based on the labels you have used, i.e., spam or not spam. The algorithm uses training data and feedback from humans to learn the relationship of given inputs to a given out-put. Yann LeCun, Facebook’s chief AI scientist, who also invented the widely used convolutional neural networks (CNNs) explains:
Almost all the applications of deep learning today use supervised learning. Supervised learning is when you give the correct answer to the machine when you’re training it and then it corrects itself to give the cor-rect answer. The magic of it is that after it’s trained, it produces a correct answer most of the time in categories it’s been trained on.
UNSUPERVISED LEARNING
In unsupervised learning, the machine uses data that is unlabelled. Unsupervised learning is seen as being crucial to the progression of machine learning, as it is how human beings learn. When a baby is developing, we do not show it thousands of pictures of cats to train it to recognize a cat. We just tell the baby a few times what a cat is, and the baby learns unsupervised by observing its environment. Unsupervised learning has a very long way to go in its contribution to the field of AI, but it can be used today in effective business applications. For example, Critical Future was engaged by one of the largest manufacturers in the world to analyze its customer data with machine learning. The company gave us a data file with an open brief to draw insights from it. Since it is such a big com-pany, the data file contained 20 million data points. It would take a team of human beings years to analyze such a large data haul manually. Our consultant, Artis Luguzis, a PhD in machine learning applied a technique of unsupervised learning to the data called “clustering.”
CLUSTERING
Clustering means using the machine to identify groups without any human intervention. In other words, we let the data tell us what patterns are there. From clustering, the machine found 20 million data points of customers, translated into 20 customer groups.
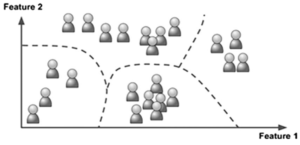
Figure 6: visual illustration of clustering
We then needed human intervention to characterize those groups and understand their relevance. The benefit of clustering is that the ma-chine is naive to the data. It doesn’t have any human biases, so it finds connections that humans would have never considered. What we found was that the 20 groups created by the machine were actually customer types: big spenders, frequent spenders, risky customers and more. This provided significant customer insight for our client.
REINFORCEMENT LEARNING
The final type of machine learning is reinforcement learning. This enables the machine to learn from interaction. The machine works by trial and error, gathering data and following reward signals. Its objective is to learn to act in a way that will maximize its expected long-term rewards. In short, the agent acts in the environment and learns by trial and error to maximize its pleasure and minimize its pain.
Reinforcement learning is based on the findings of seminal psychologist B.F. Skinner, who showed the importance of reinforcing stimuli by rewarding specific behavior and making the same thing more likely to occur in the future. Reinforcement learning is one of the main ways that human beings learn, such as when you learned to walk as a baby or learned to ride a bike or throw a baseball. You tried it and gradually improved by trial and error. Reinforcement learning can trace its origin back to the basal ganglia, which are ancient reptilian parts of the brain tied to motor control. The basal ganglia use reinforcement learning–type algorithms to help humans acquire skills.
Russell Kirsch was the first to propose using this approach in AI. He proposed that an “artificial stimulus” could use reinforcement to learn good moves in a game. Demis Hassabis, who founded DeepMind, has achieved stunning feats with reinforcement learning. Hassabis learned from his PhD studies in neuroscience that the human brain works from reinforcement learning called temporal difference learning, which is implemented by dopamine. Dopamine neurons track prediction errors that your brain is making and then strengthen synapses according to these reward signals. This insight led Hassabis to focus on reinforcement learning at DeepMind, and when he combined it with deep learning, the technology was able to massively scale up to produce deep reinforcement learning. This is what AlphaZero, the program, used to learn chess in nine hours and then beat the greatest chess-playing machine in history.
Hassabis believes reinforcement learning is much more involved in human brain function than is currently known. For example, evolution could have tacked reward signals in the human brain for gathering new information. Hassabis believes that since reinforcement learning is so fundamental to the human brain, the field will be very important for the future of AI and be-come “just as big as deep learning.”
MACHINE VISION
Just as deep learning took inspiration from how the brain works with neu-ral networks and reinforcement learning is based on how humans and animals learn, other aspects of artificial intelligence mimic human and animal abilities, such as vision. Machine vision is a fascinating sub-field of machine learning through which computers can see. Just as a person or an animal sees, machines can use vision to detect, analyze and understand images.
The business applications of machine vision are powerful. For example, Critical Future was engaged by Klinik Healthcare Solutions, a leading Finnish AI company, to develop machine vision software. Our brief was to create software that can detect skin diseases from photographs. Our consultant Brayan Impada, a PhD in machine vision, developed a pro-gram that can detect skin cancer by analyzing photographs. Users simply upload a photograph of a skin mole to the system and get back a prediction of whether the mole is malignant or benign. Since human doctors mainly use visual diagnosis for assessing whether a mole is cancerous, an AI system using machine vision can be just as effective.
NATURAL LANGUAGE PROCESSING
Not only do machines now have vision but, like human beings, they can also work with language. From using Google Translate to speaking with a virtual assistant like Alexa, we have all become familiar with computers using language. But how do they do it?
The secret is in turning words into numbers. Computers don’t under-stand language in the same way human beings do. Noam Chomsky, the great linguist and cognitive scientist, once said: “Children don’t learn language; they grow language.” We are remarkably good at understanding context and meaning, even when there is ambiguity. We are also great at understanding where one word ends and another begins, even though they may actually sound interconnected. Even neuroscientists can’t understand how our minds do this so well. For all these reasons, it is not possible to write computer code with rules for language processing. This would require too many rules, over too many languages and would be an insurmountable task.
The breakthrough came with natural language processing. This field of AI turns words into numbers and uses statistical methods to decipher meaning. Drawing on vast data lakes of words that have been created from online platforms such as Google to Facebook and beyond, natural language processing is based on language models, data and statistical tools. One popular model in the field is Word2Vec, a two-layer neural net for processing text. It swallows a given set of text and then returns the text as a set of vectors, transforming the words into a numerical form that computers can understand.
The need for such algorithms is ever-increasing since humans produce continuously expanding volumes of text each year. Natural language processing is at the center of the AI revolution, since it provides a tool for humans to communicate with computers effectively. NLP draws from many disciplines, including computer science and computational linguis-tics, in its pursuit to fill the gap between human communication and computer understanding. NLP makes it possible for computers to read text, hear speech, interpret it, measure sentiment and determine which parts are important. Machines can analyze more language-based data than humans, without fatigue and in a consistent, unbiased way.
The natural language–processing market is predicted to reach $22.3 bil-lion by 2025, and it will have broad business applications. Google recently launched Talk to Books, which uses NLP to read 100,000 books and 600 mil-lion sentences in half a second and then return the best answer it can find to any question. At Critical Future, we were asked by one of the world’s leading data providers to build an AI system that can read legal documents. The cli-ent engaged human operators to read thousands of legal documents, making standardized checks to support financial-service clients. To replace this meth-od, we developed software using natural language processing that can read the documents and make the same checks autonomously. This has saved the client hundreds of thousands of dollars in the first year of operation.
GENERATIVE DESIGN
AI is so far mimicking human intelligence in vision, learning, speech and language and, in robotics, movement. But AI can’t do everything humans can do, right? Machines can’t engineer things as human can? They can’t come up with creative new ideas, can they? Well, actually, yes, they can.
Critical Future is pioneering a new field of AI called generative de-sign, which rivals human engineers, creatives and designers. This AI software can independently create drawings, perform calculations and explore trade-offs. The role for humans is to tell the generative design software what kind of part to design. Our project is in oil and gas, and we rely on our client to propose a great deal of domain- specific expertise. We use generative design to automatically generate designs for oil and gas structures.
Generative design has already been used to design a car chassis. As far back as 2013—a long time in AI years—the start -up Autodesk teamed with stunt drivers in Los Angeles. Their aim was to develop an automated system that could determine the specifications of a race car chassis and then design it from scratch. To do this, the team applied sensors to a stripped-down race car that measured the quantities of interest, to collect the data essential for the AI. It captured data on stresses, strains, temperatures, displacements and more. A real driver test-drove the sensor- equipped car, accelerating, braking and speeding up in the process. At the end, the team had collected 20 million data points and then plugged these into Dreamcatcher, a generative design system from Autodesk.
The software came up with a design (see Figure 7) looks like some-thing from nature. This is not a coincidence. It has taken millions of years of evolution to develop the highly efficient structures of the nat-ural world, such as bones and skeletons. So the optimal design from an AI program is remarkably similar to what nature would provide. AI’s designs mirror the hand of god, or nature itself. The chassis is also asymmetrical and stronger on one side. The reason is that a car turns more often in one direction, and, therefore, the two sides are subject to different forces. Human designers have been aware of this fact for a long time but have not been able to produce such a fitting design to solve this problem. 39

Figure 7: car chassis produced by Generative Design, sourced from the book Machine, Platform, Crowd: Harnessing Our Digital Future, New York: W. W. Norton & Company, 2017.
ENSEMBLE AI
We have covered powerful narrow AI capabilities across movement, speech, language, predictive power, vision and even creative engineering. What would happen if you applied them at the same time in one creation? This is being done with compelling results through ensemble AI solutions. These solutions bring together different narrow AIs into one combined solution. A well-known example of ensemble AI is the self-driving car, which combines several narrow AIs into one overall solution. As we have seen, AI now has the following capabilities:
- Vision
- Language
- Movement
- Touch
- Smell
- Listening
- Acting
- Creativity
These narrow AI capabilities have already been combined to pro-duce a manifestation of AI that’s a lot more humanlike—androids that have many of the qualities of a human being. That is exactly what Japanese roboticist Hiroshi Ishiguro has achieved. He has designed and produced some thirty androids, most female, but he claims with some justification that his android Erica is the most humanlike robot ever created.40She has a beautiful neutral face and can hold a conversation. She understands what you are saying, moves and makes decisions. Erica is so human that her creators do not believe she is strictly a machine but represents a new category somewhere between machine and human. While this may pose philosophical questions for Westerners with a Ju-deo- Christian understanding of life, it is not so problematic in Japan. The Japanese Buddhist tradition teaches that every object has a soul, and so, of course, Erica herself also has a soul.

Figure 8: Erica a robot of Hiroshi Ishiguro
- Adapted from Infographic in Paul R. Daugherty and H. James Wilson’s Human + Machine: Reimagining Work in the Age of AI, Cambridge Massachusetts: Harvard Business Review Press, 2018
- Nick Bostrom, Superintelligence: Paths, Dangers, Strategies, Cambridge: Oxford University Press, 2016
- Pedro Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World, New York: Basic Books, 2015
- Nick Polson and James Scott, AIQ: How Artificial Intelligence Works and How We Can Harness Its Power for a Better World, (New York: St. Martin’s Griffin, 2019
- “MIT Professor Claude Shannon dies; was founder of digital communications," MIT News, http://news.mit.edu/2001/shannon
- Pedro Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake OurWorld.
- “Industrial-Strength Analytics with Machine Learning,” CIO Journal, WSJ.com, September 11, 2013, https://blogs.wsj.com/cio/2013/09/11/industrial-strength-analytics-with-machine-learning
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence, (Cambridge, Massachusetts: Harvard Business Review Press, 2017)
- Jeff Hawkins, On Intelligence
- Jeff Hawkins, On Intelligence
- Jeff Hawkins, On Intelligence
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence
- Daniel Kahneman, Thinking, Fast and Slow, New York: Farrar, Straus and Giroux, 2011
- Daniel Kahneman, Thinking, Fast and Slow.
- Nick Polson and James Scott, AIQ: How Artificial Intelligence Works and How We Can Harness Its Power for a Better World.
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence..
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence.
- Gary Kasparov with Mig Greengard, Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins.
- Andrew McAfee and Erik Brynjolfsson, Machine, Platform, Crowd: Harnessing Our Digital Future, New York: W. W. Norton & Company, 2017.
- “Are We Ready for Intimacy With Androids?” Wired, October 17, 2017, https://www.wired.com/2017/10/hiroshi-ishiguro-when-robots-act-just-like-humans/.
- Adapted from Infographic in Paul R. Daugherty and H. James Wilson’s Human + Machine: Reimagining Work in the Age of AI, Cambridge Massachusetts: Harvard Business Review Press, 2018
- Nick Bostrom, Superintelligence: Paths, Dangers, Strategies, Cambridge: Oxford University Press, 2016
- Pedro Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World, New York: Basic Books, 2015
- Nick Polson and James Scott, AIQ: How Artificial Intelligence Works and How We Can Harness Its Power for a Better World, (New York: St. Martin’s Griffin, 2019
- “MIT Professor Claude Shannon dies; was founder of digital communications,” MIT News, http://news.mit.edu/2001/shannon
- Pedro Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake OurWorld.
- “Industrial-Strength Analytics with Machine Learning,” CIO Journal, WSJ.com, September 11, 2013, https://blogs.wsj.com/cio/2013/09/11/industrial-strength-analytics-with-machine-learning
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence, (Cambridge, Massachusetts: Harvard Business Review Press, 2017)
- Jeff Hawkins, On Intelligence
- Jeff Hawkins, On Intelligence
- Jeff Hawkins, On Intelligence
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence
- Daniel Kahneman, Thinking, Fast and Slow, New York: Farrar, Straus and Giroux, 2011
- Daniel Kahneman, Thinking, Fast and Slow.
- Nick Polson and James Scott, AIQ: How Artificial Intelligence Works and How We Can Harness Its Power for a Better World.
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence..
- Ajay Agrawal and Joshua Gans, Prediction Machines: The Simple Economics of Artificial Intelligence.
- Gary Kasparov with Mig Greengard, Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins.
- Andrew McAfee and Erik Brynjolfsson, Machine, Platform, Crowd: Harnessing Our Digital Future, New York: W. W. Norton & Company, 2017.
- “Are We Ready for Intimacy With Androids?” Wired, October 17, 2017, https://www.wired.com/2017/10/hiroshi-ishiguro-when-robots-act-just-like-humans/.